
XGBoost与LightGBM算法
XGBoost 和 LightGBM 算法是 GBDT 算法的升级版,在目前机器学习中有广泛的应用。它们运算速度快、准确度高,且支持并行运算。
XGBoost算法
原理概述
XGBoost 算法比较复杂,其完整的介绍文档可以参见 https://xgboost.readthedocs.io/ 。
算法的完整原理可以在官方文档中查到。这里仅介绍一些基本的要点:
XGBoost 在 GBDT 算法上做了如下优化:
- 算法本身的优化
XGBoost 算法的损失函数加入了正则化部分,可以防止过拟合,因此泛化能力更强。
XGBoost 算法的损失函数对误差的部分做二阶泰勒展开,相比只对误差部分做负梯度(一阶泰勒)展开的 GBDT 算法更准确。
- 运行效率的优化
XGBoost 算法可以对每个弱学习器做并行选择,从而提升运行效率。
代码编写
可以通过 pip 安装 XGBoost 算法库,或者通过 Git 获取其源码。
XGBoost 算法的 Github 仓库为 https://github.com/dmlc/xgboost 。
采用 pip 需要安装 xgboost 库:
如果是通过 Git 克隆得到的,可能还需要编译得到的源码。完整的安装说明可以参见 https://xgboost.readthedocs.io/en/latest/build.html 。
如果 pip 安装出现问题,可以考虑通过 wheels 安装。xgboost 的 wheels 文件可以在 https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost 得到。
总之,在安装完成该库后,确保库中包含 xgboost.dll 文件。
xgboost 库的使用方法和 Scikit-Learn 各模型的使用方式非常类似,以下是一个简单示例:
同样有分类模型和回归模型供选择。
LightGBM算法
算法原理
LightGBM 和 XGBoost 都是对 GBDT 算法的高效实现,在原理上都是采用损失函数的负梯度作为当前决策树的残差近似值来拟合新的决策树。
LightGBM 的优势在于:训练效率高、内存使用低、准确率高、支持并行处理,适合处理大规模数据。
LightGBM 算法的官方文档为 https://lightgbm.readthedocs.io/ ,里面有对算法细节的详细介绍。
以下介绍 LightGBM 算法的一些特征:
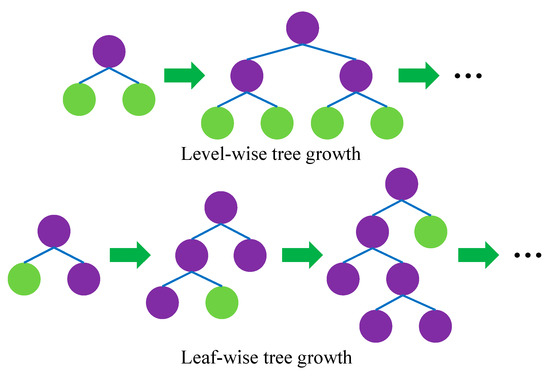
- 基于 leaf-wise 的决策树生长策略
传统的决策树算法使用的是 level-wise 生长策略,每次同一层叶结点都会发生分裂。
但是实际上一些叶结点的分裂增益较低,会浪费一部分运算资源。leaf-wise 策略每次在当前叶结点中找到分裂增益最大的结点对其分裂,这样可以提高精准度,但缺点是可能造成过拟合。
下图比较了两种分裂策略:
- 直方图算法
直方图算法又称 histogram 算法,先将连续的特征值离散化为 \\( k \\) 个整数,形成一个个箱体(bins),构造出一个宽度为 \\( k \\) 的直方图。
遍历数据时以这些离散的整数值作为索引,构造频数直方图,再根据该直方图的遍历寻找最优分割点。
这样在节点分裂时,需要排序的数量便可以大大减小。
代码编写
LightGBM 也是一个独立的库,可以借助 pip 安装:
LightGBM 的源码可以从 https://github.com/microsoft/LightGBM 得到,编译方式可以参见官方文档。
需要说明的是,LightGBM 不支持32位系统。
LightGBM 库和 XGBoost 库一样,api的调用方式都和 Scikit-Learn 类似,分类模型使用 LGBMClassifier ,回归模型使用 LGBMRegressor 。