
数据预处理
非数值类型数据处理
哑变量处理
哑变量也称虚拟变量,通常取值为 0 或 1 。例如,将“性别”取值“男”或“女”处理为 0 或 1 ,以供模型处理。
可以使用 Pandas 库的 get_dummies() 函数处理哑变量:
| salary | gender_female | gender_male | |
|---|---|---|---|
| 0 | 3000 | 0 | 1 |
| 1 | 2400 | 1 | 0 |
| 2 | 3200 | 0 | 1 |
得到的结果被拆分为两列。由于这两列数据存在多重共线性,因此可以丢弃一列:
| salary | gender | |
|---|---|---|
| 0 | 3000 | 0 |
| 1 | 2400 | 1 |
| 2 | 3200 | 0 |
这样就得到了最终的结果。
编号处理
对于多个值的情况,还可以使用编号的方式将文本内容转换成数字。这种方式需要使用Scikit-Learn 中的 LabelEncoder 类:
接着只需要用得到的结果替换原始列即可。
哑变量和编号处理这两种方式都可以将非数值数据转换成数值数据,优点是可以作为特征变量参与预测,缺点是得到的数值没有实际意义,如果将这部分数值用于计算可能会发生问题。不过对于树模型来说一般不会造成什么影响。
除此之外,在分类不多,且分类名称明确的情况下,还可以使用 DataFrame 对象的 .replace() 或 .map() 方法,前者替换特定内容;后者对每个值进行特定操作,也可以实现特定的效果:
不过这种方式在处理未知的列时,可能还需要提前使用 .value_counts() 方法查看列中都存在哪些值。
正常化与标准化
去除异常值
假设要处理如下的数据:
可以发现数据中包含了部分过于悬殊的数值。这些数值有可能会给模型造成一定的污染,需要将其去除。
对于大量数据肯定不能人工去除,以下是两种检测异常值的思路:
利用箱体图观察
箱体图(box plot)是一种用于显示一组数据分散情况的统计图,可以通过设定标准将数值识别为异常值。
下图表达了箱体图的概念:
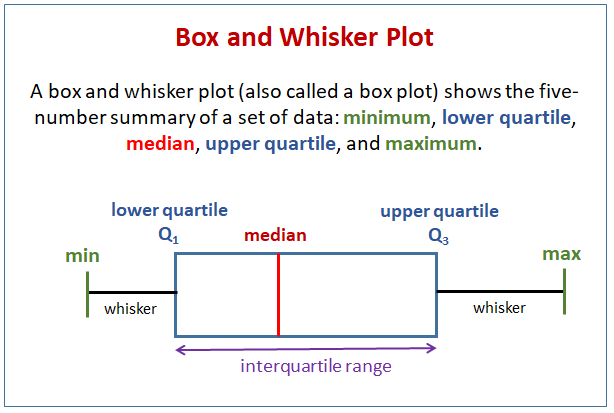
将数据的下四分位记为 \\( Q_1 \\) ,上四分位记为 \\( Q_3 \\) ,上四分位和下四分位的差值记为 \\( \text{IQR} \\) ;箱体上界为 \\( Q_3 + 1.5 \times \text{IQR} \\) ,下界为 \\( Q_1 - 1.5 \times \text{IQR} \\) ,即为正常值的范围。
可以直接调用 DataFrame 的 .boxplot() 方法绘制箱体图:
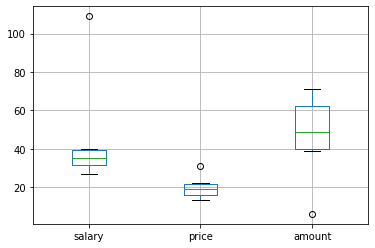
可以看到每个数据各有一个异常值。
利用标准差检验
当数据服从标准正态分布时,99% 的数据与均值的距离在 3 个标准差内,95% 的数字与均值的距离在 2 个标准差内。
在不用太严格的情况下,将阈值设定为 2 个标准差,当数据与均值的距离超出该阈值,即可认为它是异常值。
根据标准差检验异常值的代码如下:
| salary | price | amount | |
|---|---|---|---|
| 0 | False | False | False |
| 1 | False | False | False |
| 2 | False | False | False |
| 3 | True | False | False |
| 4 | False | False | False |
| 5 | False | False | False |
其中第三行对每列数据实行 Z-score 标准化,具体的内容接下来会介绍。
得到的结果包含布尔值,可以根据结果剔除或修改含有异常值的数据。
数据标准化
在介绍K近邻算法时提到过数据标准化(数据归一化),主要目的是消除不同特征变量量纲级别相差过大造成的不利影响。
min-max标准化
min-max标准化(Min-Max Normalization)也称离差标准化,它利用原始数据的最大值和最小值把原始数据转换到 \\( [0,1] \\) 区间内,转换公式为:
其中 \\( x \\) 和 \\( x^* \\) 分别为转换前和转换后的值,\\( \max \\) 和 \\( \min \\) 为原始数据的最大值和最小值。
对于以下数据:
使用 Scikit-Learn 对以上数据用min-max标准化处理的方法为:
得到的结果都包含在 0~1 内。
Z-score标准化
Z-score 标准化也称均值归一化,通过原始数据的均值(mean)和标准差(standard deviation)对数据执行标准化处理。
该方式标准化后的数据符合标准正态分布,即均值为 0 ,标准差为 1 。它所使用的转换公式如下:
其中 \\( \text{mean} \\) 和 \\( \text{std} \\) 为原始数据的均值和标准差。
使用代码对数据 Z-score 标准化处理的代码与 min-max 标准化很类似:
总之,不仅仅是K近邻算法,还有许多基于距离的算法也受到量纲的影响,需要提取对数据进行标准化处理。
数据分箱与特征筛选
数据分箱
数据分箱就是将一个连续变量离散化,可分为等宽分箱与等深分箱:
- 等宽分箱:每个分箱的差值(值的范围)相等
- 等深分箱:每个分箱的样本数一致
可以简单地用 Pandas 的 cut 函数执行等宽分箱:
利用得到的结果,可以通过分组获取每个分箱的样本数:
分箱的主要目的是为接下来介绍的特征值筛选作准备。
特征筛选
构造一个模型可能需要一些特征变量,但有时数据提供的特征变量可能达到几十个,这时不可能将所有的特征变量都用于训练,需要筛选出一些典型的特征变量。
WOE值
WOE值即证据权重(Weight of Evidence),反应了某一变量的特征区分度。
要计算一个变量的WOE值,需要先对该变量分箱处理,分箱后的第 \\( i \\) 个分箱内数据的WOE值的计算公式为:
\\( P_{y_i} \\) 是第 \\( i \\) 个分箱中目标变量取值为 1 的个体占整个样本中所有目标变量取值为 1 的个体比例,\\( P_{n_i} \\) 是取值为 0 的个体占比。
依照定义,可以对以上公式简单变换:
变换后,WOE值也可以理解为:分箱后第 \\( i \\) 个分箱中取值为 1 与取值为 0 的比值与整体比值的差异。如果这个差异很大,就说明各个分箱的区分度很高,能够较好地分类。
如果各个分箱,即不管数据取值范围如何,这个差异都很小,那就说明该变量对分类没什么影响,该变量就不够有特征性了。
通过以下代码,分箱并初步检查变量对分类的影响:
| all | purchased | not purchased | |
|---|---|---|---|
| EstimatedSalary | |||
| (14865.0, 42000.0] | 95 | 39 | 56 |
| (42000.0, 69000.0] | 104 | 8 | 96 |
| (69000.0, 96000.0] | 125 | 31 | 94 |
| (96000.0, 123000.0] | 38 | 30 | 8 |
| (123000.0, 150000.0] | 38 | 35 | 3 |
仅从该表中,也能看出变量对结果的影响。接下来利用上述公式计算WOE值:
| all | WOE | |
|---|---|---|
| EstimatedSalary | ||
| (14865.0, 42000.0] | 95 | 0.224441 |
| (42000.0, 69000.0] | 104 | -1.898675 |
| (69000.0, 96000.0] | 125 | -0.523076 |
| (96000.0, 123000.0] | 38 | 1.907987 |
| (123000.0, 150000.0] | 38 | 3.042967 |
IV值
IV值即信息量(Information Value),能较好地反映特征变量的预测能力。特征变量对预测结果的作用越大,IV值就越高。
各个分箱的特征变量通过以下公式计算:
其中 \\( \text{IV}_i \\) 为一个特征变量第 \\( i \\) 个分箱的 \\( \text{IV} \\) 值。总的 \\( \text{IV} \\) 值就是每个分箱对应的值之和:
通过之前得到的 \\( \text{WOE} \\) 值,就可以方便地计算 \\( \text{IV} \\) 值:
处理多重共线性
对多元线性回归模型 \\( Y=k_0+k_1X_1+k_2X_2+\dots+k_nX_n \\) ,如果特征变量之间存在高度线性相关关系,则称为多重共线性(multicollinearity),需要删去其中相关的变量。
除了完全共线性,模型可能还存在近似共线性:
如果存在不全为 0 的 \\( a_i \\) ,其中 \\( v \\) 为随机误差项,则称特征变量之间存在近似共线性。
DataFrame 的 .corr() 方法可以立即检查各个特征变量之间的相关系数,从而判断变量之间是否具有多重共线性:
| GNP.deflator | GNP | Unemployed | Armed.Forces | Population | Employed | |
|---|---|---|---|---|---|---|
| GNP.deflator | 1.000000 | 0.991589 | 0.620633 | 0.464744 | 0.979163 | 0.970899 |
| GNP | 0.991589 | 1.000000 | 0.604261 | 0.446437 | 0.991090 | 0.983552 |
| Unemployed | 0.620633 | 0.604261 | 1.000000 | -0.177421 | 0.686552 | 0.502498 |
| Armed.Forces | 0.464744 | 0.446437 | -0.177421 | 1.000000 | 0.364416 | 0.457307 |
| Population | 0.979163 | 0.991090 | 0.686552 | 0.364416 | 1.000000 | 0.960391 |
| Employed | 0.970899 | 0.983552 | 0.502498 | 0.457307 | 0.960391 | 1.000000 |
其中主对角线上是变量与自身的共线性,自然是 1 ;表中有许多变量之间的相关系数都超过了 0.95 ,可以认为它们之间有很强的共线性。
相关系数只是判断多重共线性的充分条件,可能会有遗漏的情况。为了更加严谨地判断是否存在多重共线性,可以使用方差膨胀系数(Variance Inflation Factor, VIF)法检验。
方差膨胀系数的计算公式如下:
其中 \\( \text{VIF}_i \\) 是衡量自变量 \\( X_i \\) 与其它自变量的方差膨胀系数,\\( R_i^2 \\) 即 R-square 值。
一般来说,VIF 值大于 10 ,即说明变量存在一定的多重共线性;大于 100 时多重共线性就非常严重了。
Statsmodels 库提供了一种检验多重共线性的方法:
结果显示数据之间存在严重的多重共线性,需要删除一些特征变量,否则会使线性回归模型的预测能力下降。
过采样与欠采样
建立模型时可能遇到样本分类比例非常不均衡的情况,例如建立疾病预测模型时,未得病样本的比例应该远小于得病的。这部分失调的比例会浪费更多时间去拟合,导致测试结果不佳。
此时,可以选择过采样或
过采样
最简单的过采样方法是随机过采样,具体方式是在样本较少的分类中随机抽取一个旧样本拷贝为新样本,这样重复随机拷贝直到两个分类的样本数差不多为止。但是该方式会因为样本的重复,容易造成过拟合。
一种改进的方法是SMOTE法,即合成少数类过采样技术。这种方法根据样本不同将其分为两类,每次随机选取少数类中的一个样本,找到离该样本点最近的若干样本点,并在连线上随机取点生成新的样本点。
下图展示了这种过采样原理:
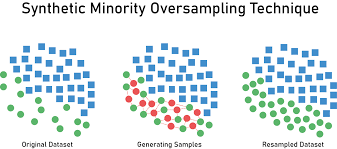
该方法可以看作让分类“变密”但不“变散”的一个过程
imbalanced-learn 是一个专门用于处理数据不均衡问题的工具库。可以通过 pip 直接安装,还可以通过克隆源代码的方式安装:
(sci) PS D:\MachineLearning\demo> cd imbalanced-learn
(sci) PS D:\MachineLearning\demo\imbalanced-learn> pip install .
使用以下代码可以执行随机过采样,同时统计过采样前后的结果;
可以看到,过采样后两个分类的样本数一致。
类似地,以下的代码可以执行SMOTE法过采样:
欠采样
与过采样相反的操作是欠采样。欠采样是直接舍弃大分类中的大部分样本,使两者样本数相等。因此欠采样的样本在搭建模型时可能导致欠拟合。
imbalanced-learn 库同样支持直接生成欠采样样本: