链表的概念
上一节介绍了顺序表。为了避免插入和删除元素的线性开销,这里提出了链表的概念。链表的实现是一种非连续的存储,这样在插入和删除时表的整体或部分无需全部移动。
下图表达了链表的思想:

从上图可以看到,链表的每一个结构都由两部分组成:
- 数据域:数据元素本身
- 指针域:指针
next 指向该元素的后继元素结构
特别地,最后一个单元的 next 指针指向 NULL ,代表链表的结束。
为了执行打印表或 find 操作,只需要将一个指针传到该表的第一个元素,然后用若干 next 指针遍历该表即可。
这种操作是线性时间的,它的开销会比顺序表实现的大。不过插入和删除的操作会比顺序表小很多:

在遍历表时,A3元素便会被直接忽略,达到删除的效果。
- 插入命令只需要通过一次
malloc() 调用从系统中获得一个新单元,并调整两次指针:
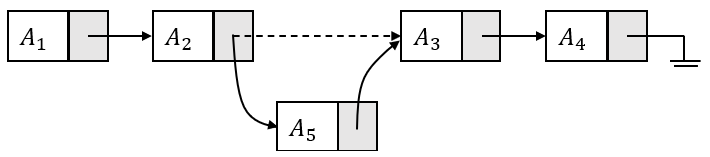
仔细研究上图可以发现,以上实现仍然存在一些问题:
- 在未知后一个元素的情况下,从起始端逐个插入元素并不容易实现;
- 对表的第一个元素的插入方法比较特殊,它不涉及修改调整前指针;
- 当删除表元素时,无法通过一个现有元素简单找出前一个元素
因此需要留出一个标志节点元素,称为表头节点。通过表头,可以很容易地管理表元素:

接下来演示链表的具体实现,以及如何通过表头管理表。
链表的实现
节点的结构定义如上文所述:
typedef struct node_t {
int elem;
struct node_t* next;
} node;
根据链表的定义,测试一个链表是否是空链表是很容易的:
/* Return true if link list is empty */
int isempty(node* header) {
return header->next == NULL;
}
类似地可以测试一个位置是否已经位于链表的末尾:
/* Return true if current node is the last position */
int islast(node* nd) {
return nd->next == NULL;
}
注意两者的区别在于是用表头还是节点进行判断。
链表的增删改查
查找
有了链表的实现,比较容易的操作就是查找元素。只需要从表头或任意链表位置开始,不断向后查询节点,直到找到所需要的元素即可:
/* Return a node in certain position, NULL if not found */
node* find(int value, node* nd) {
node* nextnode = nd->next;
while (nextnode != NULL && nextnode->elem != value)
nextnode = nextnode->next;
return nextnode;
}
while 判断条件利用了 && 运算符的短路原理,一旦发现到达结尾,就不再判断值的存在性。
删除
由于删除节点比增加节点方便实现,先介绍删除节点。
删除节点的操作相对容易,只需要找到节点的前驱节点 previous ,再通过以下语句:
previous->next=previous->next->next;
即可完成删除。
为了找到前驱元素,首先需要编写一个函数来寻找它:
/* if previous node is not found, last returned */
node* findp(int value, node* header) {
node* prev = header;
while (prev != NULL && prev->next->elem != value)
prev = prev->next;
return prev;
}
这个函数的整体实现与 find() 类似,只不过它直接跨节点查找以确保定位上一个节点。
配合 findp() 例程,可以很容易编写出删除链表元素的函数:
/* delete first occurence of element in link table */
void delete(int value, node* header) {
node* prev = findp(value, header);
if (!islast(prev)) {
prev->next = prev->next->next;
free(prev->next);
}
}
注意在 findp() 例程中,可能发生找不到前驱元素的情况,此时返回的是最后一个元素,要对这种情况加以判断。
插入
观察以上插入图示,可以看出,为了保证链表在任何时候不断裂,插入的步骤需要按以下顺序进行:
- 将新节点的
next 指针顺着旧节点指向下一个元素 - 断开旧节点的
next 指针,指向新节点
这两个步骤不能反向进行。
因此,相应的C语言实现如下:
/* insert after prev, header implementation assumed */
void insert(int value, node* prev) {
node* temp = malloc(sizeof(node));
if (temp == NULL) {
/* raise warnings */
return;
}
temp->elem = value;
temp->next = prev->next;
prev->next = temp;
}
创建与删除链表
创建链表
上述只涉及了对现有链表的操作,但是没有涉及如何创建链表。
创建链表的思路很简单:首先声明一个表头及其指针,再声明一个指向当前元素的指针;每添加一个节点元素,利用当前指针将当前节点的 next 指针指向它:
int main(void) {
node* header = malloc(sizeof(node)); // create header node
node* pres = header;
for (int i = 1; i < 5; i++) { // create some nodes
node* temp = malloc(sizeof(node));
if (temp && pres) {
temp->elem = i;
temp->next = NULL;
pres->next = temp;
pres = pres->next;
}
}
/* codes */
return 0;
}
这里的当前指针就如一根线一样将所有节点串起,它起引导当前节点指向下一个节点的作用。
还要注意的是,每新建一个节点元素,都需要暂时将其当做尾元素来看待。
删除链表
有了新建链表的基础,删除链表也不显得复杂了。删除链表要求从表头开始,每遇到一个节点,将其 next 指针置空,并释放其占据的内存空间。
因此需要借助两个指针完成删除链表:一个指针保存 next 节点,一个指针用于将当前节点 free() 。
删除链表的C语言实现为:
/* delete link list and each element */
void clear(node* header) {
node* pres, * temp;
pres = header->next;
header->next = NULL;
while (pres != NULL) {
temp = pres->next;
free(pres);
pres = temp;
}
}
