
双链表
双链表的概念
有时需要倒序扫描链表,但是标准方法实现却非常复杂。这里提出双链表(doubly linked list)的概念,本质上就是在链表的基础上增加了一个前向指针 prev 。下图展示了双链表的原理:

双链表可以减少向前检索的时间,但代价是一个附加的链,增加了空间的需求,同时也增加了插入的开销,因为有更多指针需要定位。
双链表需要一个 isheader() 函数来判断当前结点是否为表头:
/* Return true if current node is the header position */
int isheader(node* nd) {
return nd->prev == NULL;
}
双链表的插入
下面先看双链表的插入。如果需要向双链表中插入元素,需要完成以下几个工作:
- 修改前一结点的
next元素和当前结点的prev元素 - 修改当前结点的
next元素和后一结点的prev元素
操作的图示为:

双链表的插入只需要给出前面或后面的结点作为定位即可。这里以给出前面的结点为例编写代码:
/* insert after prior, header implementation assumed */
void insert(int value, node* prior) {
node* latter = prior->next;
node* temp = malloc(sizeof(node));
if (temp == NULL) {
/* raise warnings */
return;
}
temp->elem = value;
temp->next = latter; // adjusting between this and next
latter->prev = temp;
temp->prev = prior; // adjusting between this and prev
prior->next = temp;
}
双链表的删除
双链表在删除时,需要调整的指针个数比单链表更多,但是双链表的删除操作比单链表简单,因为前驱元素的信息是现成的。
下图展示了双链表的删除操作:

可以正序扫描双链表以找出所需元素,也可以倒序扫描。这里给出了一种倒序扫描的删除函数:
/* delete right first occurence of element in linked list */
void rdelete(int value, node* last) {
node* tmp = last;
while (tmp && tmp->elem != value)
tmp = tmp->prev;
if (tmp && !isheader(tmp)) {
tmp->prev->next = tmp->next;
tmp->next->prev = tmp->prev;
free(tmp);
}
}
从双链表的删除中,就可以明白双链表的 find 和 rfind 如何操作。
循环链表
循环链表的概念
让链表的最后一个元素指向第一个元素或表头是一种实用的做法,它可以有表头也可以没有表头,并且也可以是双向链表。
下图展示了一个有表头的单链循环链表:
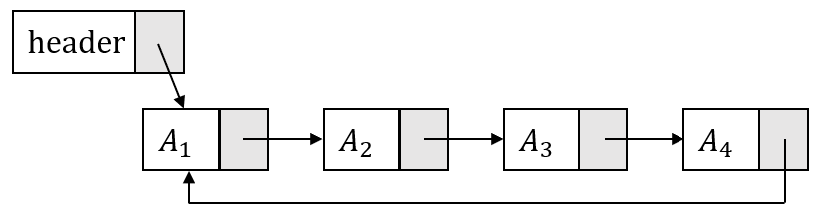
下图展示了一个没有表头的双链循环链表:

下面以带有表头的双向循环链表为例,介绍如何创建循环链表。
循环链表的结点就是于双链表的结点,但是循环链表还需要在第一个和最后一个元素间创建结点,因此比双链表的创建多了一步:
/* Create double-linked circular list */
node* init(node* header, int length) {
header = (node*)malloc(sizeof(node));
header->prev = NULL;
header->next = NULL;
header->elem = 0;
node* list = header;
for (int i = 0; i < length; i++) {
node* body = (node*)malloc(sizeof(node));
body->prev = NULL;
body->next = NULL;
body->elem = 0;
list->next = body;
body->prev = list;
list = list->next;
}
/* doubly linking between first and last nodes */
list->next = header;
header->prev = list;
return header;
}
给定表头元素和循环链表长度,可以轻松遍历整个循环链表。但是,循环链表对首末结点的测试被影响了。